
I modelli all’avanguardia odierni, tra cui Gemini, Veo e Imagen di Google e Claude di Anthropic, vengono addestrati e utilizzati su unità di elaborazione tensoriale (TPU). Per molte organizzazioni, l’attenzione si sta spostando dall’addestramento di questi modelli alla creazione di interazioni utili e reattive con essi. Le architetture dei modelli in costante evoluzione, l’ascesa dei flussi di lavoro agentici e la crescita quasi esponenziale della domanda di potenza di calcolo definiscono questa nuova era dell’inferenza. In particolare, i flussi di lavoro agentici che richiedono orchestrazione e stretto coordinamento tra calcolo generico e accelerazione ML stanno creando nuove opportunità per chip personalizzati e architetture di sistema ottimizzate verticalmente. Ci stiamo preparando da tempo a questa transizione e oggi annunciamo la disponibilità di tre nuovi prodotti basati su chip personalizzati che offrono prestazioni eccezionali, costi inferiori e nuove funzionalità per l’inferenza e i carichi di lavoro agentici: Ironwood, la nostra TPU di settima generazione, sarà disponibile nelle prossime settimane. Ironwood è progettato appositamente per i carichi di lavoro più impegnativi: dall’addestramento di modelli su larga scala e l’apprendimento rinforzato (RL) complesso, all’inferenza AI ad alto volume e bassa latenza e al model serving. Offre un miglioramento delle prestazioni di picco pari a 10 volte rispetto alla TPU v5p e prestazioni per chip superiori di oltre 4 volte sia per i carichi di lavoro di addestramento che di inferenza rispetto alla TPU v6e (Trillium), rendendo Ironwood il nostro chip personalizzato più potente ed efficiente dal punto di vista energetico fino ad oggi. Nuove istanze Axion basate su Arm ®. N4A, la nostra macchina virtuale della serie N più conveniente fino ad oggi, è ora disponibile in anteprima. N4A offre un rapporto prezzo-prestazioni fino a 2 volte superiore rispetto alle VM basate su x86 di generazione attuale comparabili. Siamo inoltre lieti di annunciare che C4A metal, la nostra prima istanza bare-metal basata su Arm, sarà presto disponibile in anteprima.
Ironwood e queste nuove istanze Axion sono solo le ultime novità di una lunga storia di innovazione nel campo dei chip personalizzati di Google, che include TPU, Video Coding Unit (VCU) per YouTube e cinque generazioni di chip Tensor per dispositivi mobili. In ogni caso, realizziamo questi processori per consentire progressi rivoluzionari in termini di prestazioni che sono possibili solo attraverso una profonda co-progettazione a livello di sistema, con ricerca sui modelli, sviluppo di software e hardware sotto lo stesso tetto. È così che abbiamo realizzato il primo TPU dieci anni fa, che a sua volta ha portato all’invenzione del Transformer otto anni fa, l’architettura che alimenta la maggior parte dell’AI moderna. Ha anche influenzato progressi più recenti come la nostra architettura Titanium e il raffreddamento a liquido avanzato che abbiamo implementato su scala GigaWatt con un tempo di attività dell’intera flotta pari a circa il 99,999% dal 2020.
 |
 Nella foto: unità di distribuzione del raffreddamento di terza generazione, che forniscono raffreddamento a liquido a un superpod Ironwood. Nella foto: unità di distribuzione del raffreddamento di terza generazione, che forniscono raffreddamento a liquido a un superpod Ironwood. |
Ironwood: il percorso più veloce dall’addestramento dei modelli all’inferenza su scala planetaria La risposta iniziale a Ironwood è stata incredibilmente entusiasta. Anthropic è affascinata dagli impressionanti miglioramenti in termini di rapporto prezzo-prestazioni che accelerano il percorso dall’addestramento di modelli Claude su larga scala alla loro distribuzione a milioni di utenti. Infatti, Anthropic prevede di accedere a un massimo di 1 milione di TPU: “I nostri clienti, dalle aziende Fortune 500 alle startup, si affidano a Claude per il loro lavoro più critico. Poiché la domanda continua a crescere in modo esponenziale, stiamo aumentando le nostre risorse di calcolo mentre spingiamo i confini della ricerca sull’AI e dello sviluppo dei prodotti. I miglioramenti apportati da Ironwood sia nelle prestazioni di inferenza sia nella scalabilità della formazione ci aiuteranno a crescere in modo efficiente, mantenendo la velocità e l’affidabilità che i nostri clienti si aspettano”. –
James Bradbury, Head of Compute, Anthropic
Ironwood viene utilizzato da organizzazioni di tutte le dimensioni e in tutti i settori industriali: “La nostra missione in Lightricks è definire l’avanguardia della creatività aperta, e questo richiede un’infrastruttura di AI che elimini gli attriti e i costi su larga scala. Ci siamo affidati alle TPU di Google Cloud e al suo enorme dominio ICI per ottenere la nostra rivoluzionaria efficienza di training per LTX-2, il nostro modello generativo multimodale open source leader. Ora, mentre entriamo nell’era dell’inferenza, i nostri primi test ci rendono molto entusiasti di Ironwood. Crediamo che Ironwood ci consentirà di creare immagini e video più sfumati, precisi e fedeli per i nostri milioni di clienti in tutto il mondo”. –
Yoav HaCohen, Research Director, Lightricks
“At Essential AI, our mission is to build powerful, open frontier models. We need massive, efficient scale, and Google Cloud’s Ironwood TPUs deliver exactly that. The platform was incredibly easy to onboard, allowing our engineers to immediately leverage its power and focus on accelerating AI breakthroughs.” –
Philip Monk, Infrastructure Lead, Essential AI
Il vantaggio di AI Hypercomputer: hardware e software progettati insieme per risultati più rapidi ed efficienti A questo hardware si aggiunge un livello software progettato congiuntamente, il cui obiettivo è massimizzare l’enorme potenza di elaborazione e la memoria di Ironwood e renderlo facile da usare durante tutto il ciclo di vita dell’AI. Per migliorare l’efficienza e le operazioni della flotta, siamo lieti di annunciare che i clienti TPU possono ora beneficiare delle funzionalità di Cluster Director in Google Kubernetes Engine. Questo include la manutenzione avanzata e la consapevolezza della topologia, per una pianificazione intelligente e cluster altamente resilienti.Per il pre-addestramento e il post-addestramento, condividiamo anche i nuovi miglioramenti apportati a MaxText , un framework LLM open source ad alte prestazioni, per facilitare l’implementazione delle più recenti tecniche di ottimizzazione dell’addestramento e dell’apprendimento rinforzato, come il Supervised Fine-Tuning (SFT) e il Generative Reinforcement Policy Optimization (GRPO). Per l’inferenza, abbiamo recentemente annunciato un supporto migliorato per le TPU in vLLM, che consente agli sviluppatori di passare dalle GPU alle TPU o di eseguire entrambe con solo alcune piccole modifiche alla configurazione, e GKE Inference Gateway, che bilancia in modo intelligente il carico tra i server TPU per ridurre la latenza del time-to-first-token (TTFT) fino al 96% e i costi di servizio fino al 30%. Il nostro livello software è ciò che consente ad AI Hypercomputer di garantire prestazioni elevate e affidabilità per l’addestramento, la messa a punto e l’esecuzione di carichi di lavoro AI impegnativi su larga scala. Grazie alle profonde integrazioni in tutto lo stack, dalle ottimizzazioni hardware a livello di data center al software aperto e ai servizi gestiti, le TPU Ironwood sono le nostre TPU più potenti ed efficienti dal punto di vista energetico fino ad oggi. Scopri di più sul nostro approccio alla co-progettazione di hardware e software qui. Axion: ridefinire il calcolo generico La creazione e la gestione di applicazioni moderne richiede sia acceleratori altamente specializzati che un’elaborazione generica potente ed efficiente. Questa era la nostra visione per Axion, le nostre CPU personalizzate basate su Arm Neoverse®, che abbiamo progettato per offrire prestazioni, costi ed efficienza energetica convincenti per i carichi di lavoro quotidiani.Oggi stiamo ampliando il nostro portafoglio Axion con: N4A (anteprima), la nostra seconda VM Axion per uso generico, ideale per microservizi, applicazioni containerizzate, database open source, batch, analisi dei dati, ambienti di sviluppo, sperimentazione, preparazione dei dati e attività di web serving che rendono possibili le applicazioni di intelligenza artificiale. Per saperne di più su N4A, clicca qui. C4A metal (anteprima), la nostra prima istanza bare-metal basata su Arm, che fornisce server fisici dedicati per carichi di lavoro specializzati come lo sviluppo Android, i sistemi automobilistici di bordo, i software con requisiti di licenza rigorosi, le farm di test di scala o l’esecuzione di simulazioni complesse. Per saperne di più su C4A metal.
 Con gli annunci odierni, il portafoglio Axion comprende ora tre potenti opzioni: N4A, C4A e C4A metal. Insieme, le serie C e N consentono di ridurre il costo totale di gestione del business senza compromettere le prestazioni o i requisiti specifici del carico di lavoro. Con gli annunci odierni, il portafoglio Axion comprende ora tre potenti opzioni: N4A, C4A e C4A metal. Insieme, le serie C e N consentono di ridurre il costo totale di gestione del business senza compromettere le prestazioni o i requisiti specifici del carico di lavoro. 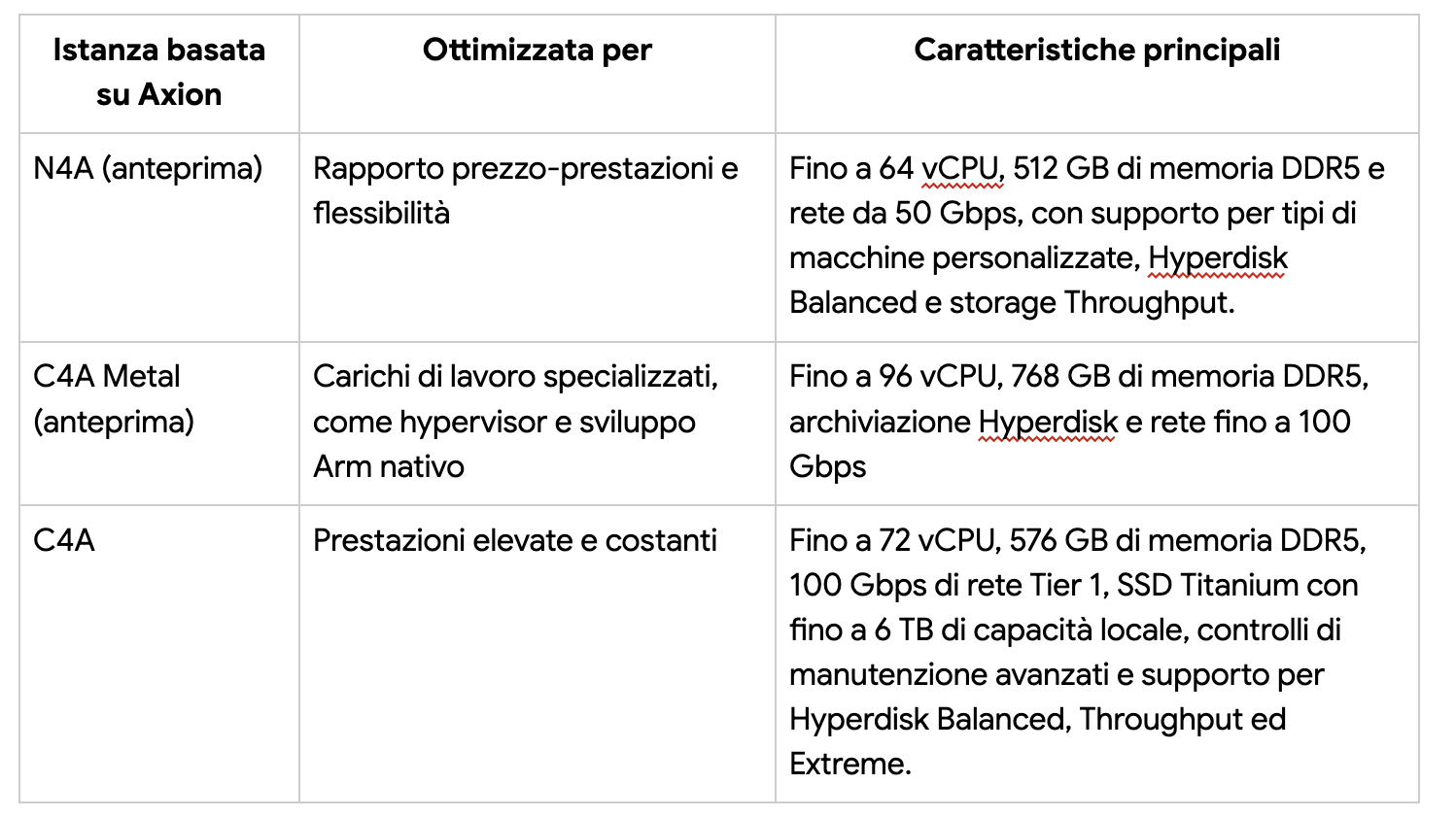 |
L’efficienza intrinseca di Axion lo rende anche un’opzione preziosa per i moderni flussi di lavoro di AI. Mentre acceleratori specializzati come Ironwood gestiscono il complesso compito di model serving, Axion eccelle nella struttura operativa: supporta la preparazione di grandi volumi di dati, l’acquisizione e l’esecuzione di server applicativi che ospitano le vostre applicazioni intelligenti. Axion sta già avendo un impatto sui clienti: “In Vimeo, ci affidiamo da tempo ai Custom Machine Types per gestire in modo efficiente la nostra enorme piattaforma di transcodifica video. I nostri test iniziali sulle nuove istanze N4A basate su Axion sono stati molto convincenti, sbloccando un nuovo livello di efficienza. Abbiamo osservato un miglioramento del 30% delle prestazioni per il nostro carico di lavoro di transcodifica principale rispetto a VM x86 comparabili. Questo indica un percorso chiaro per migliorare la nostra economia unitaria e scalare i nostri servizi in modo più redditizio, senza modificare il nostro modello operativo”. –
Joe Peled, Sr. Director of Hosting & Delivery Ops, Vimeo
“In ZoomInfo gestiamo una piattaforma di data intelligence di grandi dimensioni in cui l’efficienza è fondamentale. Le nostre pipeline di elaborazione dei dati principali, fondamentali per fornire informazioni tempestive ai nostri clienti, funzionano ampiamente su Dataflow e servizi Java in GKE. Nella nostra anteprima delle nuove istanze N4A, abbiamo misurato un miglioramento del 60% in termini di rapporto prezzo-prestazioni per questi carichi di lavoro chiave rispetto alle loro controparti basate su x86. Questo ci consente di scalare la nostra piattaforma in modo più efficiente e di fornire più valore ai nostri clienti, più rapidamente”. –
Sergei Koren, Chief Infrastructure Architect, ZoomInfo
“La migrazione al portafoglio Axion di Google Cloud ci ha offerto un vantaggio competitivo fondamentale. Abbiamo ridotto il nostro consumo di risorse di calcolo del 20% mantenendo una latenza bassa e stabile con le istanze C4A, come il nostro servizio di backend Supply-Side Platform (SSP). Inoltre, C4A ci ha permesso di sfruttare Hyperdisk con esattamente gli IOPS di cui abbiamo bisogno per i nostri carichi di lavoro stateful, indipendentemente dalle dimensioni dell’istanza. Questa flessibilità ci offre il meglio di entrambi i mondi, consentendoci di vincere più aste pubblicitarie per i nostri clienti e migliorando significativamente i nostri margini. Stiamo ora testando la famiglia N4A eseguendo alcuni dei nostri carichi di lavoro chiave che richiedono la massima flessibilità, come il nostro servizio di inoltro API. Siamo lieti di comunicare che diverse applicazioni in esecuzione in produzione consumano il 15% in meno di CPU rispetto alla nostra infrastruttura precedente, riducendo ulteriormente i nostri costi e garantendo al contempo che l’istanza giusta supporti le caratteristiche del carico di lavoro richieste”. –
Or Ben Dahan, Cloud & Software Architect, Rise
Una potente combinazione per l’AI e l’elaborazione quotidiana Per avere successo in un’era caratterizzata da architetture di modelli, software e tecniche in costante evoluzione, è necessaria una combinazione di acceleratori AI appositamente progettati per l’addestramento e il servizio dei modelli, insieme a CPU efficienti e generiche per i carichi di lavoro quotidiani, compresi quelli che supportano le applicazioni AI. In definitiva, sia che utilizziate Ironwood e Axion insieme o che li combiniate con le altre opzioni di elaborazione disponibili su AI Hypercomputer, questo approccio a livello di sistema vi offre la massima flessibilità e capacità per i carichi di lavoro più impegnativi.
Registratevi oggi stesso per provare Ironwood, AxionN4A oC4A metal.